当可观测遇到serverless
背景
可观测(监控)的产品形态,注定了其数据是写 >> 读的
市面上大多数的技术,均都对写做了大量优化
而对读却往往“无能为力”,开并发似乎是人们能做到的“极限”,但还是限于单机的瓶颈
溯源
读不能高性能的原因,其实可以大致归为以下几点:
- 与局部性更高的写相比,读往往是”随机“的,而随机往往是性能受制的根本原因
- 即使 ssd 技术已经出现多年,但硬盘的速度仍是大多数系统的瓶颈所在,所以才有了业界的
google monarch,facebook beringei等基于内存的 tsdb 出现 - 企业发展到一定程度,成本问题就一定会摆在台面上,谈必及
ROI,降本提效
那有什么方法/技术,是可以改善/解决这些问题的呢?
曙光
serverless,自 aws 2014 年推出 Lambda,faas 大火。
这里不细说 serverless、lambda、faas 的定义,只关注它的特性:
- 事件驱动
- 按量收费
- 扩展性好
再结合可观测的读场景:
- 非长期运行
- 有突发查询,并一次获取大量数据
- “成本敏感”
似乎与 faas 的使用场景 match
业界
下面看看业界是怎么使用 serverless 解决可观测数据读取能力不足的问题的。
Cortex Query Frontend
Cortex Query Frontend 最早在 2019 年由 Tom Wilkie 提出,其设计其实可以用下面这张图表示

位于 query frontend 下方的 query 不直接提供服务,而是消费由 frontend 切割后的查询。
这让我不由想起 golang 并行的趣图
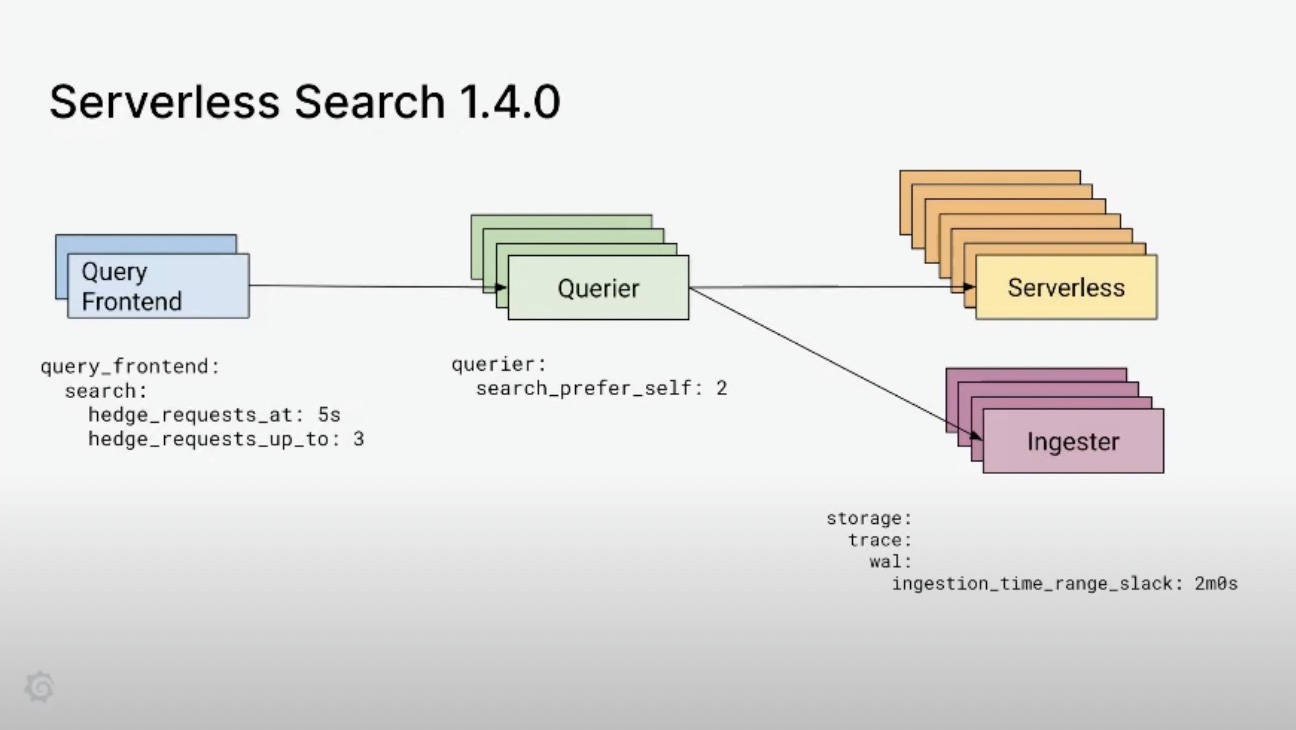
Tempo Backend Search
与 Cortex 的架构一脉相承,用于 trace 的 tempo 最近推出了试验性质的Backend search,其中就有使用 serverless 的部分,其主要架构如下
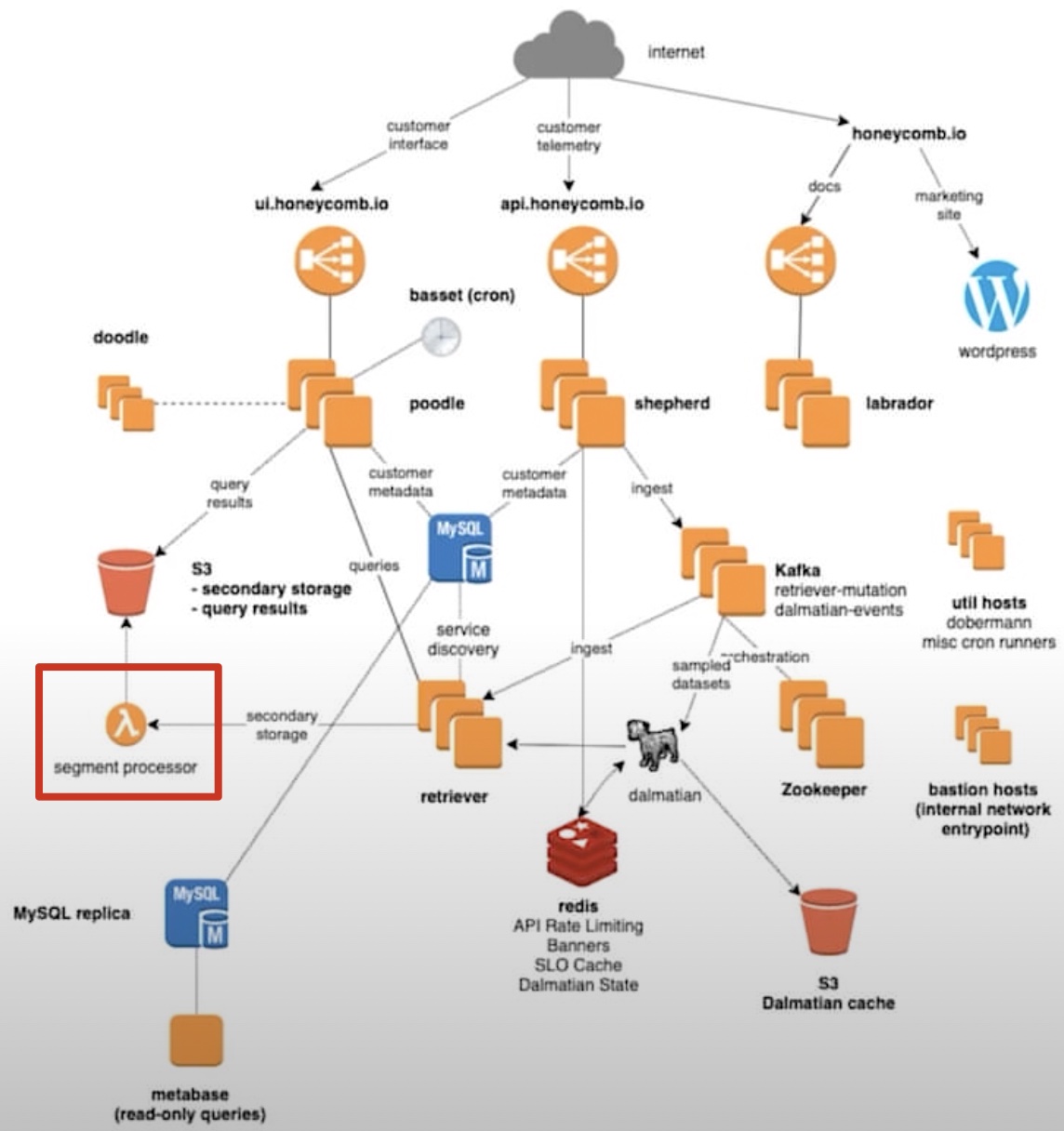
Honeycomb Retriever
如果说,cortex, tempo 还处于比较少人使用,或是试验阶段
honeycomb 已将 lambda 用在了生产环境中,而且产出了很多生产级别的经验
honeycomb 的顶层架构图如下描述,lambda 用于查询存储在 s3 上的数据
结尾
serverless 作为近年来大火的技术/产品,很适合可观测数据查询场景使用。相信其可以在可观测领域中中大放异彩。
-EOF-