浅谈监控层次模型
开局一张图,剩下全靠编。
-
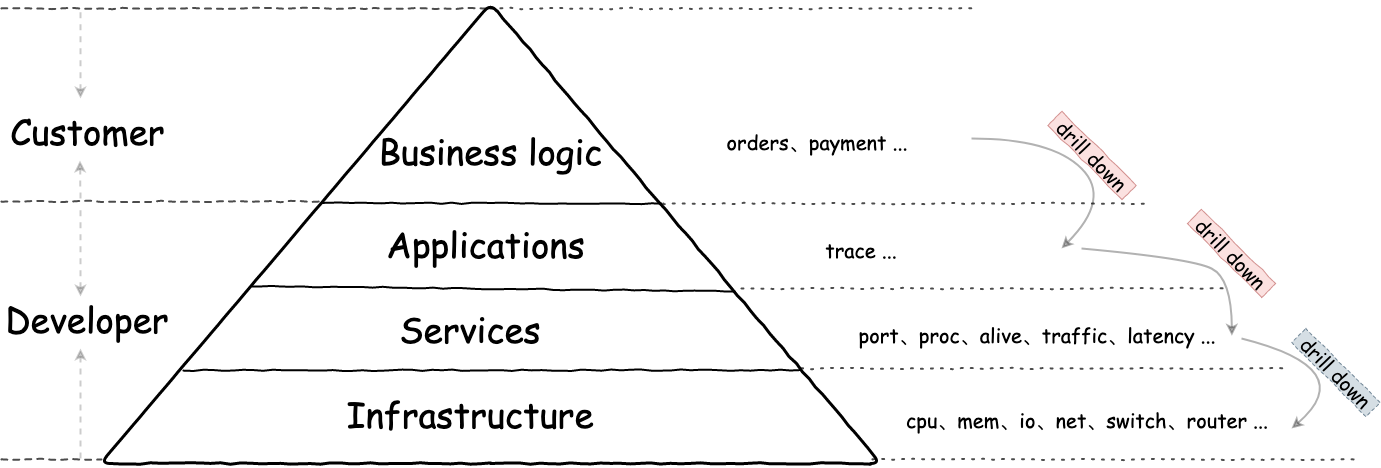
监控系统从使用者角度,一般可分为客户和开发同学
- 客户,只关注业务
- 开发同学,关注应用、服务与基础设施(9102年了,不应该再关注,下文详谈)
-
对监控的使用方式应该是
Top-down的,而不应该是Bottom-up -
监控开发者在建立其基础框架后,应尽快满足用户
Top-down的需求- 实时聚合,无论是效率还是成本,一定是无法满足需求的(例如动辄单次上万条曲线的实时计算)
- 预聚合是业界的趋势,例如 prometheus 的
recording rules
-
drill down一定是解决开发同学使用监控系统最大痛点的有效手段-
问题在哪里?
- 监控系统只提供数值型的一条条曲线,而开发同学想在曲线上看
raw logs - 开发同学想上报 traceID。而携带 traceID 的曲线可能会打爆监控系统的时序数据库
- 监控系统只提供数值型的一条条曲线,而开发同学想在曲线上看
-
如何解?
- 监控系统提供能力(异构的存储模型),能从应用曲线下钻到服务,再到下游服务。见上图红框的
drill down
- 监控系统提供能力(异构的存储模型),能从应用曲线下钻到服务,再到下游服务。见上图红框的
-
-
为什么说开发同学同学不应该再关注基础设施?上图到基础设置的
drill down为何是灰色?- 单体时代早已过去,如今已经是容器化时代,十个八个的实例挂掉,不应该影响全局
- 应该关注什么?
- 应用是否健康
- SLO 是否达标
- 本季度还有多少分钟的不可用时长供你
挥霍,用于创新与开拓 - 至于单个实例用多少内存、cpu 是否掉底,随它去吧
-
未来的监控应该是什么样的?
drilllllllllll down, 甚至 down 到 log(开发同学的最爱)observability是大势所趋
-EOF-