Falcon存储做过的那些优化
我司监控系统的底层存储架构使用的是 open-falcon,作为非常流行的中小企业监控解决方案,open-falcon非常优秀。
但在我司,指标量一度达到3亿+,且受限于成本等原因。falcon的存储组件就暴露出了一些性能问题。
本文从一个开发者的角度,阐述自本人接手以来对 graph(open-falcon的存储组件) 做过的一些优化工作,欢迎各位指正。
多路I/O
背景
2017年下半年。
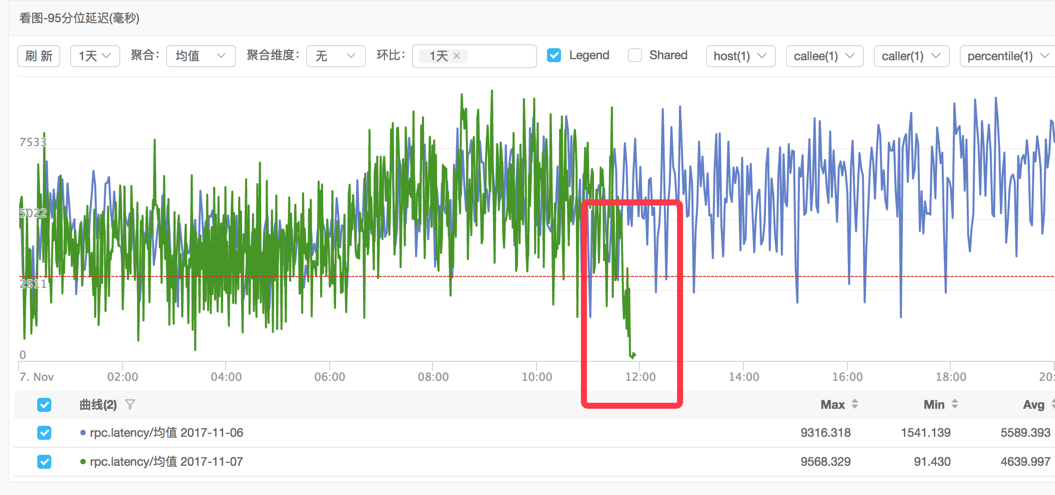
当时我们看图的latency tp95一直在5s以上,为了提升用户体验,要将这个延迟降下来。此为背景。
分析
graph的查询逻辑是,先读cache,cache不满足再从RRD文件中获取。
因此我们在代码中埋点,分别统计了readFromCache和readFromRRD的latency,结果readFromCache的tp95在300ms左右,而readFromRRD的对应值则达到了1s+。
所以接下来重点跟进方向就是读取RRD文件的逻辑。从代码上看,从RRD文件获取数据的读路径如下:
|
|
参见 api/graph.go 和 rrdtool/rrdtool.go
然后rrdtool.go/sync_disk.go::ioWorker()从io_task_chan获取对应task后进行I/O操作。
读路径经过pprof分析后,并没有耗时太多的地方。
而经过分析ioWorker()这个函数,发现 ioWorker() 只有1个goroutine在工作。而如果只是为了避免同时读写同一RRD文件这么做,似乎有些太低效了。
有了这样的思路后,问题就变成了如何拆分I/O,使得一把锁变成多把锁。当时在组内有2种思路:
- 进行读写拆分
- 按
series ID进行拆分
如果按照读写拆分,就由1路I/O变成了2路I/O,读 + 写。这样的拆分,在读写拆分仍不能满足性能的需求时,不可避免的要进行再次拆分。而且,读写2路拆分,要考虑对一个RRD文件的同时读写问题,就变得更加复杂了。
基于上面的考虑,决定按照series ID进行I/O拆分。代码很简单,参见 这个diff
而优化后的效果,如下图所示。tp95 latency的值达到了预期。
小结
其实,理解多路I/O的优化思路很简单,如下图所示,从只能1个1个投入的存钱罐,变为多路分拣的硬币分拣机。

Sprint问题
背景
同样是2017年下半年。
早期graph为了方便,在代码的很多地方使用fmt.Sprintf函数,而这个函数的性能是很烂的。
分析
直接show一个benchmark:
|
|
bench的结果:
|
|
可以看出,对于字符串的连接,使用+比使用Sprintf性能要好上2个数量级,同时减少了内存分配。
小结
优化的效果参见 这个PR。
对于golang等gc类语言来说,减少内存分配次数、复用对象等,是减轻gc压力非常有效的手段。这个PR 也佐证了这个理论。
hash不均问题
背景
2018年上半年。
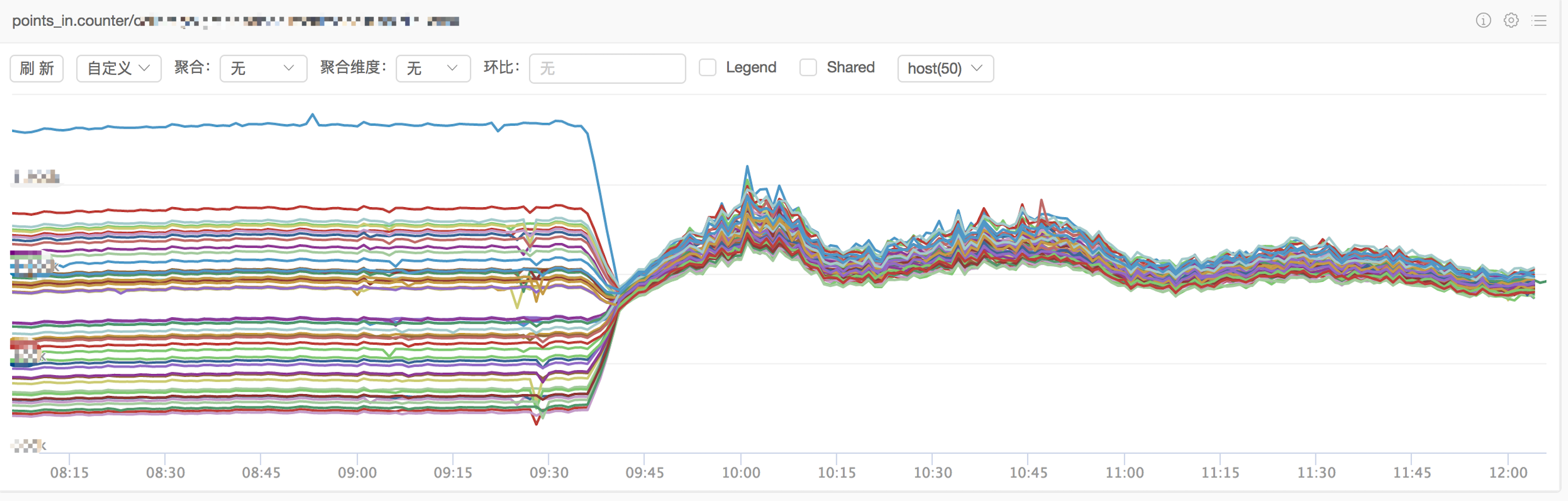
在解决了latency高等问题之后,又遇到了新的问题。graph的实例,流量非常不均匀。points_in这个代表每秒进入graph实例点数的指标,在不同实例间相差很大,最大的值是最小值的2倍以上。
分析
使用一个小demo描述这个问题:
|
|
了解 open-falcon 的同学可能知道,open-falcon 监控数据点的写路径,是将监控数据点的series ID通过一致性哈希计算,再push到对应的graph实例。而上述代码,就是写路径GetNodes(获取graph实例) 的核心逻辑。
上面将实例数设置为50,样本数设置为500w,虚拟节点则与open-falcon的官方设置相同,设置为500。那么这50个实例,分配结果是如何的呢?
为了方便,直接看最大值和最小值的差异。结果如下,最小值为65286,最大值为134657。相差较大,graph实例的流量差异,就是从这里产生的。
|
|
而经过验证,简单的将虚拟节点的数量提高,并不会提高均匀度。以下是将虚拟节点设置为10000的结果:
|
|
open-falcon 使用的一致性哈希实现是 stathat/consistent,一个非常简单的一致性hash实现,其hash算法使用的是 crc32。
在非加密hash算法的实现中,crc32无论是在性能还是均匀度上都不是优选。下面对比了几种常见的hash算法在性能上的差异:
|
|
可以看到,相对fnv32和murmur32,crc32在性能方面完败。
最后还加入了sha1的对比,相对于非加密hash算法,sha1的性能更弱一些。
除了考量性能,还需要看各个hash算法均匀度,是否满足需求。以下是在上述模拟场景之下,几个流行hash算法的均匀度对比结果,仍是模拟500w样本,使用50个node,计算结果:
|
|
上述结果,表现最差的是crc32,表现最好的是murmur32。因为时间久远,具体的结果没有记录下来,感兴趣的同学可以自行验证。
BTW,上述结果只代表本文所述环境,不具通用性。
小结
综合性能和均匀度2个方面的考量,最终我们选用了murmur32替换原有的crc32。
虚拟节点数则设置为10000。经过验证,虚拟节点数从500到10000,计算进入graph实例的样本数的方差值,后者是前者的1/5,会更均匀一些。而更高的虚拟节点数,虽然能得到更均匀的结果,但初始化的时间开销会增加很多,例如10000个虚拟节点需要13s左右,而20000个虚拟节点则需要28s,设置为50000个虚拟节点,则需要75s。
下图是优化的效果对比,可以看到在切换前后,进入graph实例的点数均匀程度,有了明显的提升。
替换的过程也不麻烦,感兴趣的可以参考 open-falcon 更换hash算法 一文。
内存"泄漏"问题
背景
2018年下半年。
经过上述的几番优化,graph已经解决了因单路I/O导致的I/O瓶颈,替换掉了浪费性能的Sprintf,更换了更优更均匀的murmur32 hash算法。
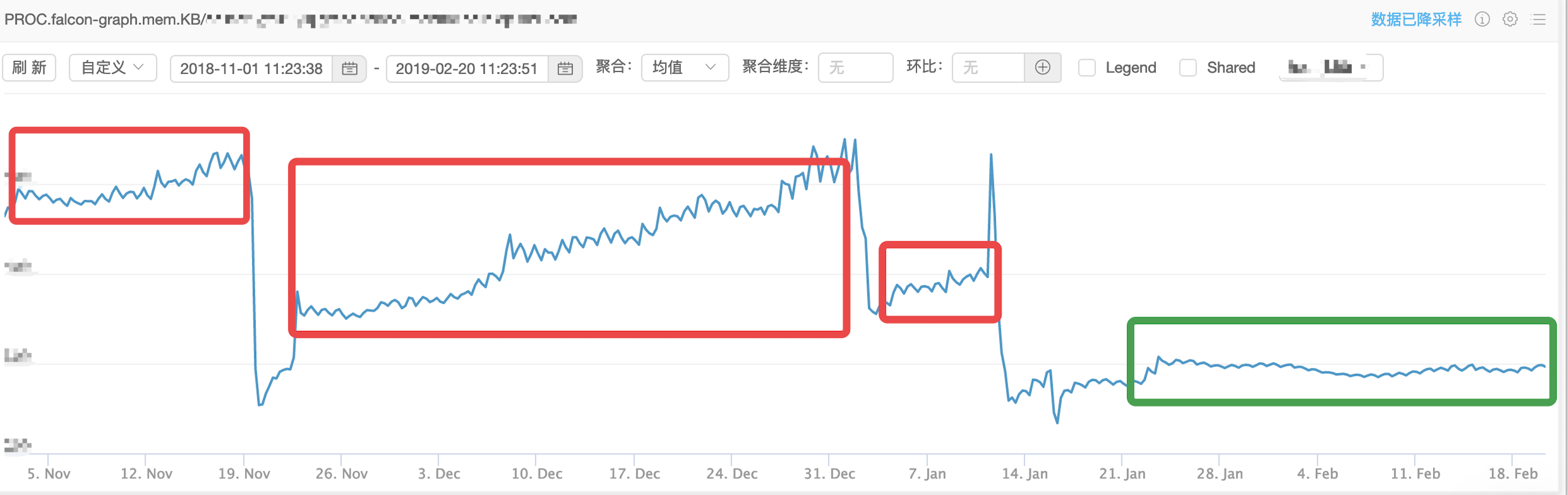
但仍有一个问题一直在困扰着我,如鲠在喉。那就是随着时间的增长,graph实例的内存使用量会慢慢的涨上来。
分析
既然是慢慢的涨,那首先考虑到的肯定是内存泄漏问题。
经过对heap的inuse分析之后,发现问题出在graph的cache逻辑。graph的cache是只增加不减少的,也就是说,所有series,无论是活跃的还是不活跃的,都会一直常驻于堆内存中。
找到问题点,就很好解决了。解决方案如下:
- 干掉无用的 History store
- 对 cache对象,做定期清理,例如
每30分钟清理过去12小时不活跃的series。
如下图描述的是过去4个月graph实例的内存使用情况,前面3个红框的内存都是缓慢增长的,而绿框位置则是优化后的效果,已经相对平稳:
小结
优化要结合业务特点进行。
是的,这个小结只有上面这么一句话 :)。
结尾了
对于监控系统的优化,还在进行中。当然也有很多case没有放在这里。
例如使用基于 Gorilla 开发的cacheserver,承载了50%以上的查询请求,latency却仅是graph的1/10等。
这些优化留待后续再慢慢分享吧。
-EOF-