调用服务端随机性连接超时case一例
现象
业务同学反馈,A服务调用B服务有连接超时
环境
- src:A服务, 以下均用src代指
- dst:B服务, 以下均用dst代指
- B服务通过lvs + nginx的方式对外服务
- A服务连接超时设置为500ms
排查过程
- 因src表现为大量连接超时,所以应用层(包括nginx和均无应用层日志),遂直接抓传输层的包。
- 使用其它机器而非线上机器测试并抓包(效果相同)
测试命令
- src不断的tcp连接dst(此处dst特指lvs vip)的8000端口
- 每次设置递增源端口
- 设置3s超时
|
|
src表现如下

dst表现如下
- 如何判断相同tcp流: 使用tcp seq
- 本处dst指lvs的某个backend, 即其中一个nginx节点

抓包分析
- 14:39:38.043935, src发出syn
- 14:39:38.069170, dst收到syn,但并未回syn,ack
- 14:39:41.043515, src重传相同seq的syn
- 14:39:41.068833, dst收到重传syn
- 14:39:41.068842, dst发出syn,ack
此时src已经到达超时时间,发rst
阶段性结论
dst明明收到syn,却没有立即回复syn,ack,有异常。
这种现象一般发生在syn半连接队列满了才会发生。(其实未必,还有一种场景,见[3])
但我们线上的syn队列的长度是4096,且打开了syn_cookie,理论上,syn半连的数量是足够用的。[1]
而且重要是的,syn,ack是tcp/ip协议栈回复的。
既然syn队列不是问题,而与syn队列最相关的就是accept队列,所以查看accpet队列情况
|
|
上述返回结果,inrouter00这台机器的overflowed数量明显比其它节点的结果要大(大一个数量级)。
而且,在执行测试命令后,overflowed的数量增长明显。
syn队列与accept队列的关系如下
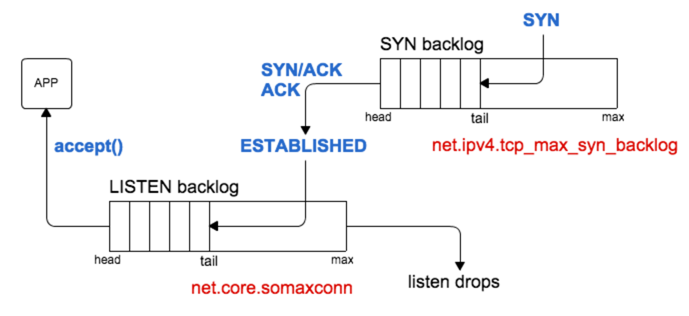
猜测
到这里能判断与应用(tengine)有关了,但tengine的error log。包括系统的message,kernel log,均没有任何的异常。
所以只能尝试重启应用。
恢复
将nginx冷重启后,故障恢复。
疑惑
- 诡异之处在于,不发syn,ack本应是syn队列满才有的行为,但发生在了一个syn队列不可能满的环境下!(这里其实不止一种场景,还是见[3])
- 在ss -nlt的结果对应nginx listen的端口,Recv-Q为0的情况下,accpet队列竟然一直overflow!(这里对Recv-Q的理解有误,见[4])
结论
如[3]源码所示,当accept队列满了的时候,如果inet_csk_reqsk_queue_young(sk) > 1,那么该syn还是会被丢弃。
题外1 关于tcp_abort_on_overflow
accept queue满了的场景抓包
tcp_abort_on_overflow=0(default)

tcp_abort_on_overflow=1

题外2 关于ss的Recv-Q
状态为Listen时
- Recv-Q: 完成了3次握手,等待accept [4]
- Send-Q: accept Queue的最大值
状态为非Listen时
- 字面含义
- 2者均是在本地缓冲区
参考
- SYN cookie
- Kernel dropping TCP connections due to LISTEN sockets buffer full in Red Hat Enterprise Linux
- Linux 2.6.32 tcp_ipv4.c about syn Queue and accept Queue
- Linux 2.6.32 tcp_diag.c about “Recv-Q”
- Is net.ipv4.tcp_abort_on_overflow good or not?
-EOF-