cacheserver - 内存TSDB的设计思想
cacheserver是什么?
- 基于facebook 的 gorilla paper 的一个服务。在内存中实现的,一个高性能、高压缩比的时序数据库
- 其原理在以前的blog中有过描述, 见 Falcon 存储优化: 高性能内存 TSDB 的诞生#数据模型的实现
- 本文主要描述在设计 cacheserver 过程中的一些思考
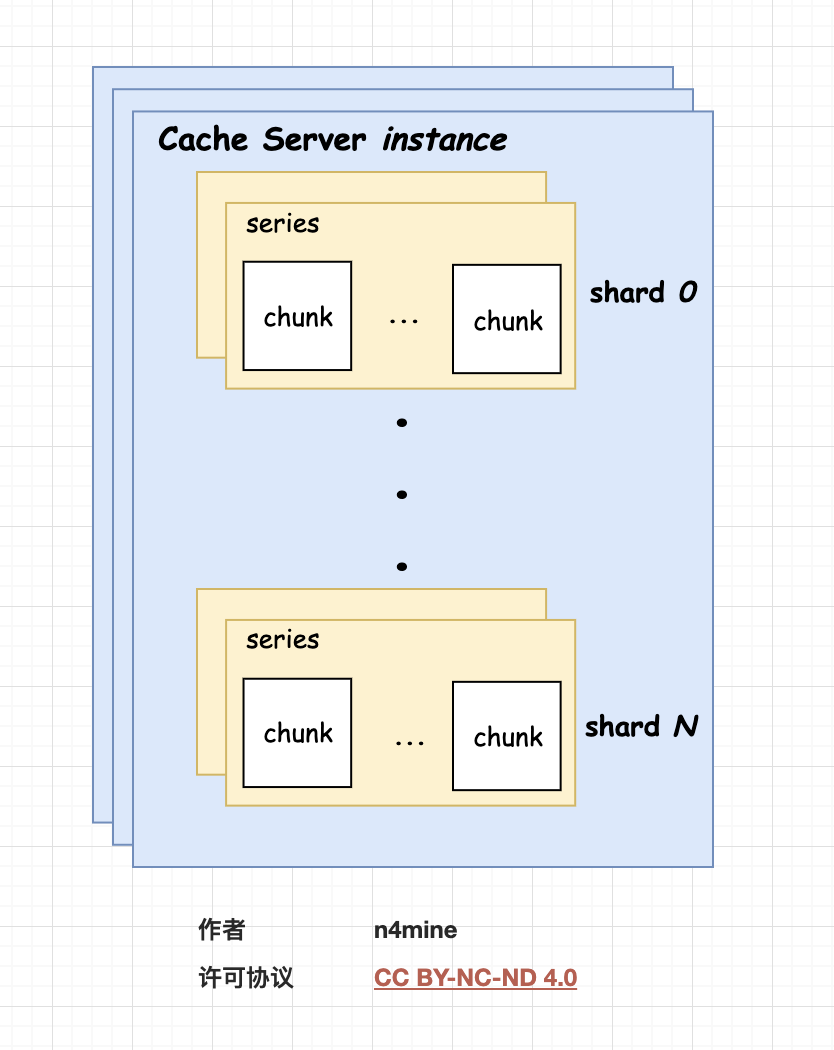
核心架构
如上图
- instance: cacheserver的实例
- shard: 一个 cacheserver instance 内的多组series chunks
- chunks: chunk slice
- chunk: 一段时间的(ts, value)数据
- series: 一条监控曲线
下面依次介绍以上每个组件, 详细的内容仍可到 Falcon 存储优化: 高性能内存 TSDB 的诞生#数据模型的实现 中查看。
instance
instance 即 cacheserver 部署的实例。
集群还是分片?分片。
shard
为什么需要 shard?分片锁降低锁冲突。
chunks/chunk
chunk 是真正存放 series 数据的结构。chunk 内存放 series 的 bit 流。 chunks 只是 chunk 的 slice,使用 ringbuffer 技术,这样可以使用固定空间来存储多个 chunk。
设计思想
为什么独立成一个服务,而不是嵌入到现有存储中
设计之初,cacheserver 的定位就是一个独立服务。
这样它可以与graph互相兜底。
例如graph挂掉了,仍可以调用cacheserver来给用户呈现最近的数据。而graph本身就是cacheserver的主存。
为什么将数据放在内存中
- 快
- gorilla 论文实现的算法压缩比高(11:1),存放热数据,内存已经足够
- redis?据了解,
baidu内部的tsdb。热数据就是放在redis中的。
怎么解决 series 爆炸问题
周期检测, 不活跃数据直接从内存中清除
怎么解决 series identify
什么是series identify, 即根据tags搜索对应的 series。
cacheserver 不解决这个问题!这是索引要解决的问题, 本质上是一个搜索问题,不该在这里解决。
cacheserver 中,每个series都是用户定义的,没有业务含义。
-EOF-